GPU model training
NVIDIA GPUs with CUDA and cuDNN for training and low-latency inference, the compute under the ML layer.
 NVIDIACUDAcuDNN
NVIDIACUDAcuDNNMachine-learning high-frequency trading infrastructure
One engine for backtest and live, proven identical by a parity gate, not a promise.
What the platform runs on, and the ML layer being built into it.
 C++
C++ Python
Python gRPC
gRPC ZeroMQ
ZeroMQ Redpanda
Redpanda ClickHouse
ClickHouse PostgreSQL
PostgreSQL NumPy
NumPy pandas
pandas Ray
Ray Spark
Spark Dask
Dask TensorFlow
TensorFlow scikit-learn
scikit-learn Hugging Face
Hugging Face MLflow
MLflow DVC
DVC ONNX
ONNX Docker
Docker Google Cloud
Google Cloud Caddy
Caddy Envoy
Envoy React
React Next.js
Next.js Svelte
Svelte Bun
Bun Leaflet
Leaflet Plotly
PlotlyNVIDIA GPUs with CUDA and cuDNN for training and low-latency inference, the compute under the ML layer.
NVIDIACUDAcuDNNRay across a multi-node cluster, orchestrated on Kubernetes and wired with high-bandwidth NVLink / InfiniBand.
Ray KubernetesNVLink
KubernetesNVLinkNVMe-backed ClickHouse for time-series, plus an object store for datasets, features, and model artifacts.
ClickHouse MinIO
MinIOExperiment tracking, data + model versioning, and a registry, reproducible from raw data to a served model.
MLflowDVCONNXA warehouse of market history, fetched over gRPC and bridged into Python, then fanned across a Ray cluster on GCP. Hidden-Markov regime fits with Gaussian emissions, parameter sweeps, and perturbation studies, Monte-Carlo, ablation, walk-forward. The same study on a laptop or on hundreds of cores.
Ray · GCPSeven guarantees the platform enforces, each a gate, contract, or test, not a slogan.
A parity gate forces research to reproduce the live run bit-for-bit, or the build fails.
A hard kill, then restart, proves jobs re-drain and terminals persist atomically.
Walk-forward folds are tested, and reading past the current index is structurally forbidden.
Suites probe their dependencies and skip honestly instead of faking a pass; and a backtest or stream whose query faults fails loud, never an empty success a client would read as “no data.”
Failure conditions are pre-committed, with a predicate on every causal-graph edge.
A reading traced to era-contamination was pulled. Failures are kept as findings.
Every long-lived stream reaps clients that drop, and malformed input is rejected before it can fault a worker thread, swept across the fleet by two robustness audits.
Seventeen services, one wire contract, the same from backtest to live.
A columnar tick store at five resolutions. The same surface drives backtest, paper, and live.
17 services on one low-latency RPC mesh, each on a shared base class.
A single, clean broker-agnostic boundary. Paper trading by default.
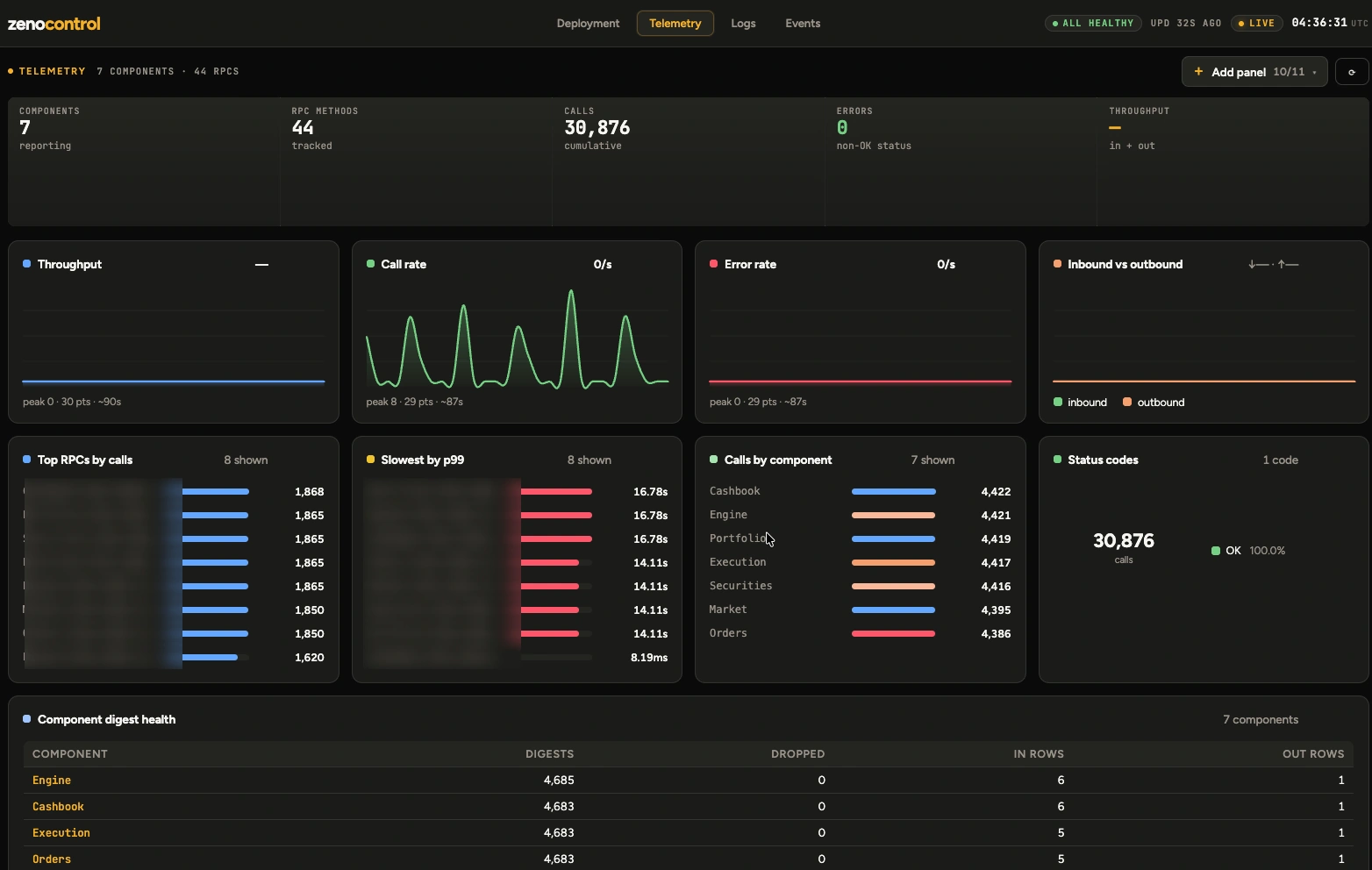
Real p50 / p95 / p99 per RPC, with correlation IDs that follow a call across services.
Eight security types, fixed-precision decimal money, closed enums at the boundary.
Positions, cash, and margin reconciled to the cent against the broker of record.
A handful of deliberate decisions, each a tradeoff we can point at.
Each service runs separate accept and IO completion queues, so taking a new connection can't head-of-line-block work already in flight.
split completion queuesThe request lifecycle, thread-pool dispatch, the self-respawning acceptor, and alarm-driven streaming, no thread per subscriber, live in one shared base every service binary inherits, with fan-out in one shared, lock-disciplined registry instead of a copy per service. A concurrency fix is one edit, in one tested place, not seventeen.
one shared base classA reliable transport carries mutations, control, and reliable streams; a lossy pub/sub transport carries high-rate market data where dropping the stalest frame is the correct behaviour. A documented rule decides which.
two transports, on purposeTimestamps are owned by the producer and preserved end-to-end. Persistence records what happened when it happened, not when it was written.
producer-owned timePrices, P&L, and cash are fixed-precision decimal throughout, so rounding error can't quietly accumulate into the books.
decimal moneyHigh-rate time-series goes through a single columnar gateway that buffers and writes in batches off the hot path, and drains on shutdown so nothing in flight is lost. Relational, constraint-bearing records go to a separate transactional store with a prepared-statement pool and forward-only migrations. A documented rule decides which.
two stores, on purposeAn internal, in-process messaging benchmark measured ~17µs p99 over 100k frames, a design datapoint, not a production SLO. No live latency numbers are committed yet.
Local where speed matters, central where truth matters, and no single box anything depends on.
Designed to survive any node or region, quorum holds.
One engine crosses from notebook to live book, proven identical by a parity gate.
Research reads the live store, fits, and writes back: one substrate, not two that drift.
Research must reproduce the live golden run bit-for-bit, or the build fails.
Rolling out-of-sample folds, first-class and tested. Lookahead-freedom is a typed contract.
Regime fits, sweeps, and scenarios fanned across a cluster, each study durable and idempotent.
The strategy you backtested runs in paper and live unchanged. Promotion is config, not a rewrite.
Drain, shut down, tail logs, and watch tail latency: the whole mesh from one console.
At the center of the loop: ingest, route, observe, persist. One wire contract.
The whole mesh is operated and observed from a single control plane, deploy across regions, stream telemetry and logs, drill into any component, and drain or shut it down live.
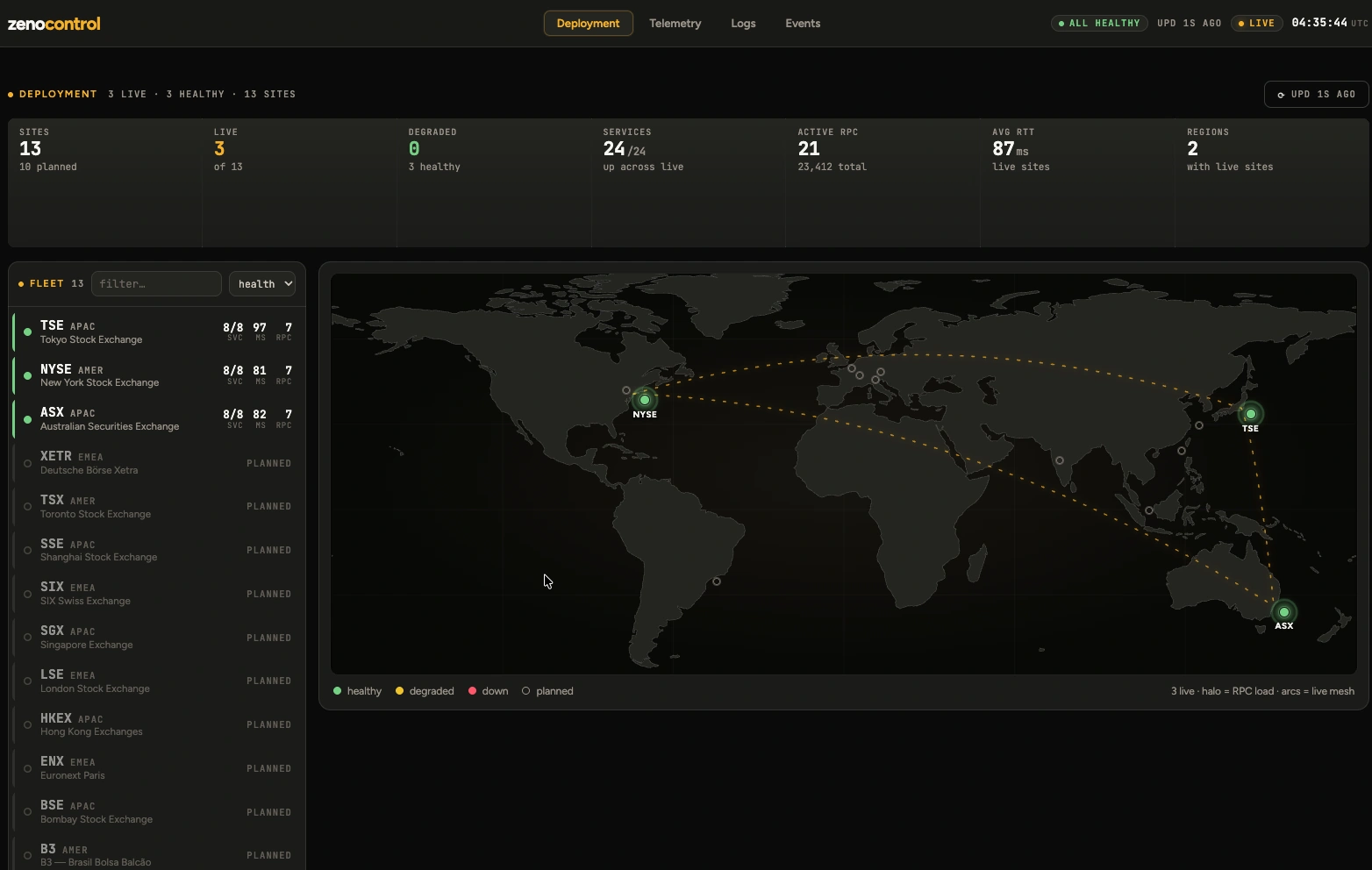
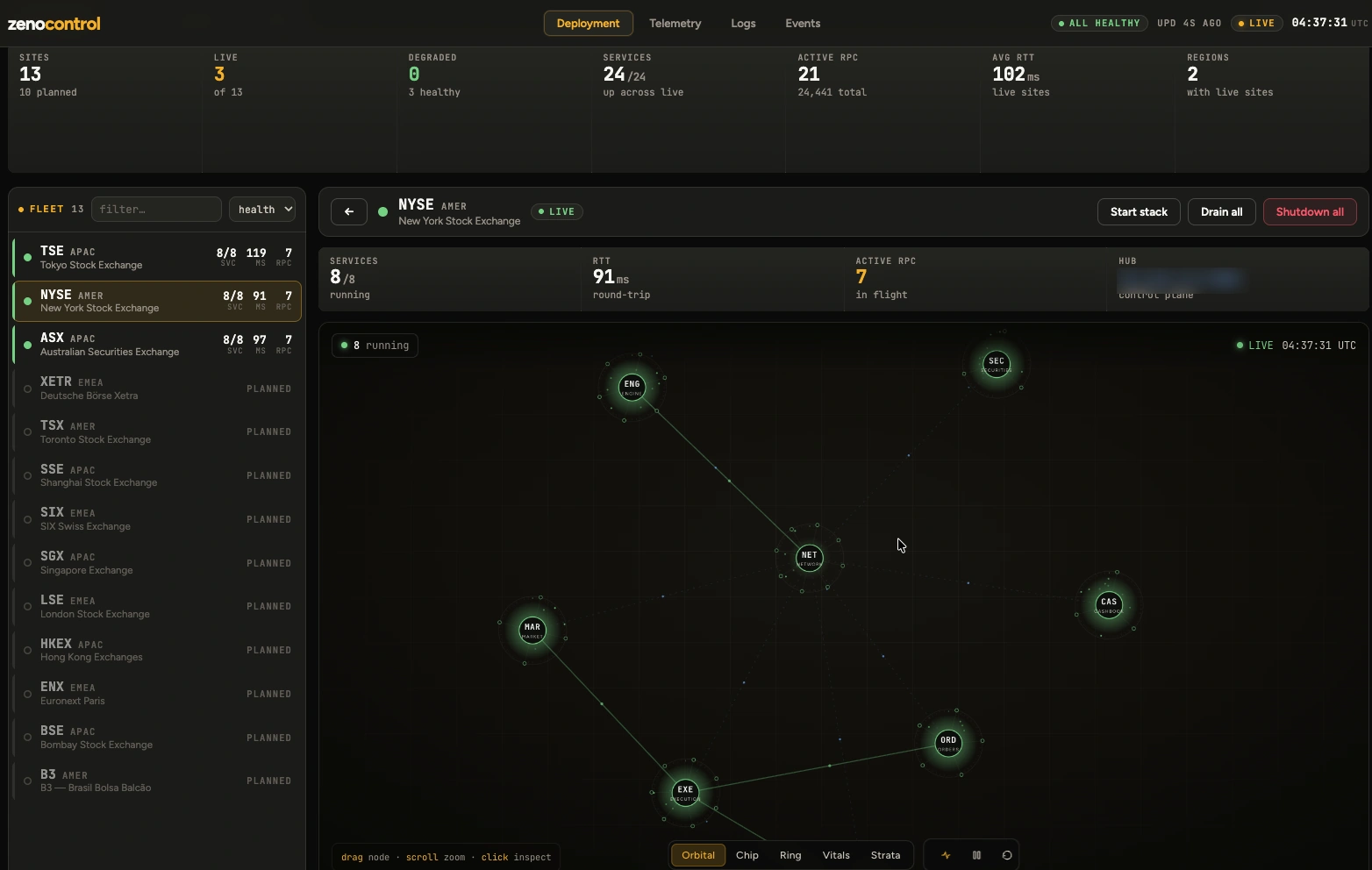
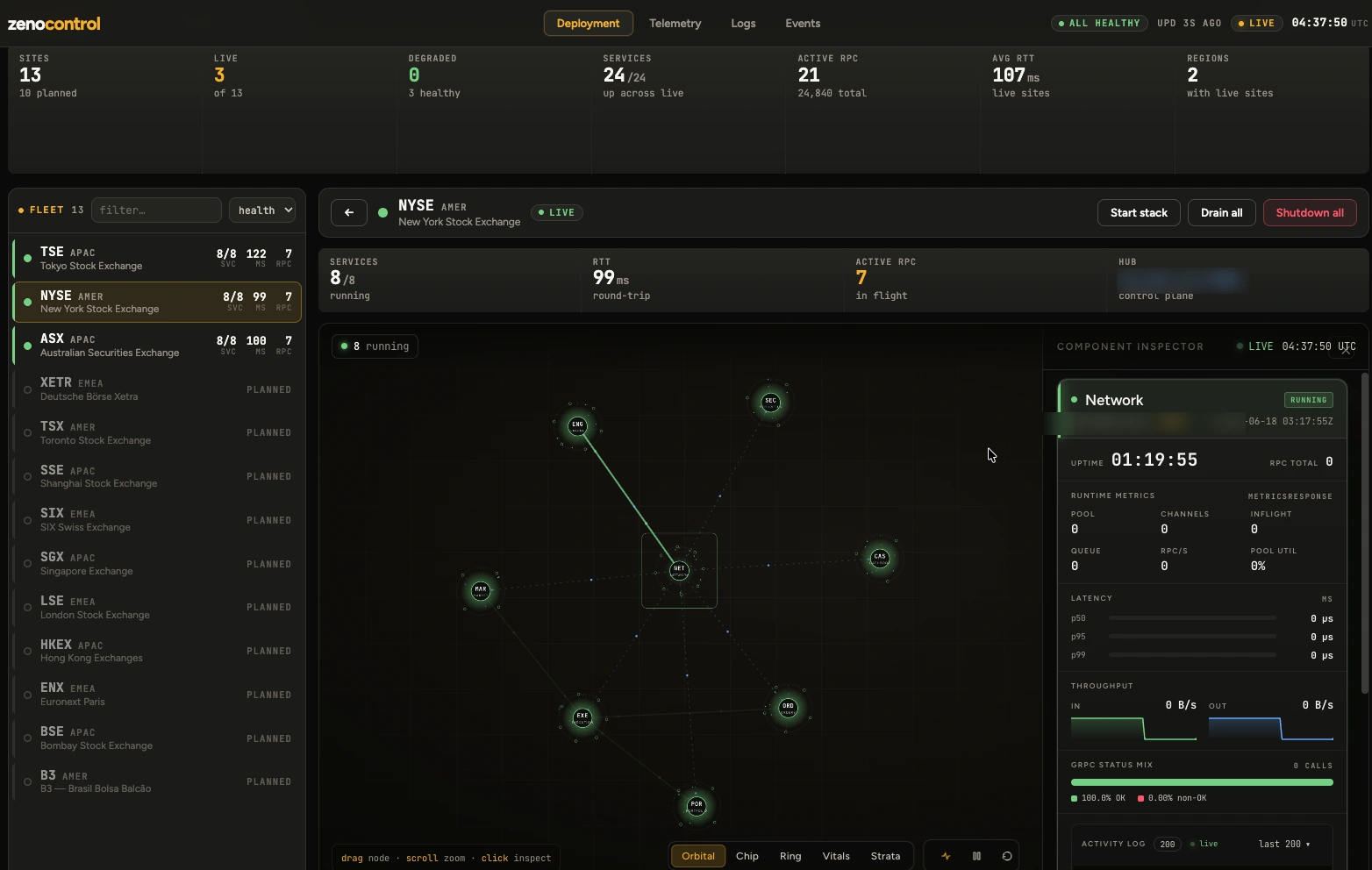
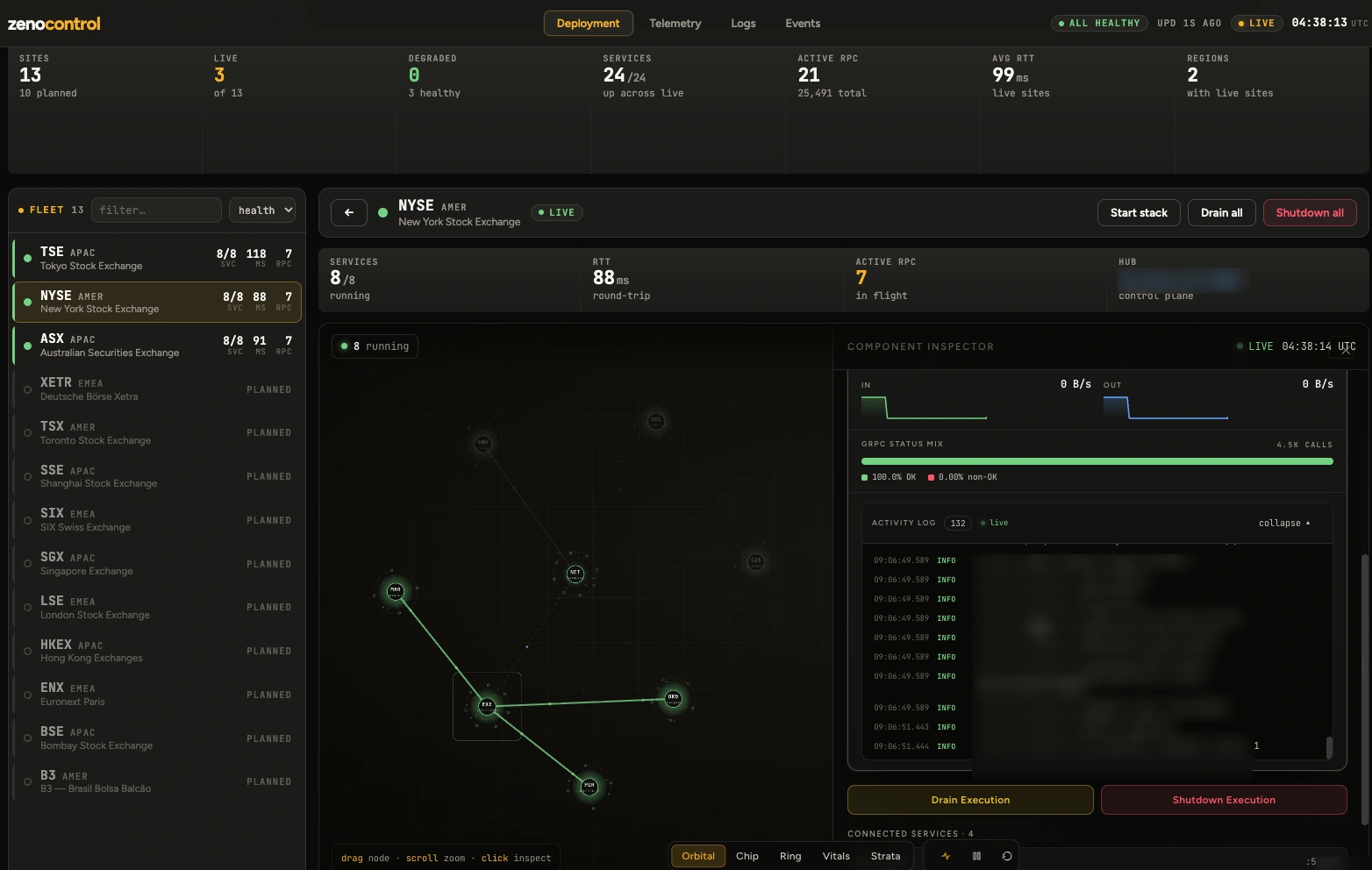
Every site on one map, live, healthy, or planned, across regions.
Seventeen services, traced as one pipeline: sources to output, control plane on top.
We treat every strategy and every model as a proposition that has to survive. Parity gates, walk-forward validation, closed catalogs, and a documented adversarial-review trail stand between a hypothesis and live capital, and when a result doesn't hold up, we withdraw it rather than dress it up.

Zeno honours Zeno of Elea (c. 490–430 BCE), the pre-Socratic philosopher whose paradoxes pioneered proof by contradiction (reductio ad absurdum) and whose doctrine of ontological pluralism held that reality admits many coexisting truths. Both ideas sit at the core of how we reason about markets.
Alpha (α) is the Greek letter that finance adopted as the benchmark for outperformance: the excess return that cannot be explained by the market itself.
Read the methodology, trace the topology, and judge the rigor yourself.